| Home - www.devmedia.com.br |
Tuning - Plano de Execução - Parte 4
Olá!
Na matéria anterior mostrei uma query cujo plano de execução nâo apresenta processo de BookMark Lookup, apesar da cláusula select requisitar uma coluna que não faz parte da composição do índice.
A query e o respectivo plano de execução encontram-se na figura abaixo:
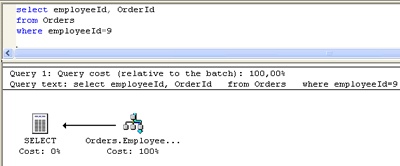
O índice utilizado EmployeesOrders é formado SOMENTE pela coluna EmployeeId; OrderId NÃO faz parte do índice. Os índices existentes na tabela Orders estão listados a seguir:
| exec sp_helpindex Orders | ||
| -------------------------------------------------------------------------------------------------------------- | ||
| index_name | index_description | index_keys |
| CustomerID | nonclustered located on PRIMARY | CustomerID |
| CustomersOrders | nonclustered located on PRIMARY | CustomerID |
| EmployeeID | nonclustered located on PRIMARY | EmployeeID |
| EmployeesOrders | nonclustered located on PRIMARY | EmployeeID |
| OrderDate | nonclustered located on PRIMARY | OrderDate |
| PK_Orders | clustered, unique, primary key located on PRIMARY | OrderID |
| ShippedDate | nonclustered located on PRIMARY | ShippedDate |
| ShippersOrders | nonclustered located on PRIMARY | ShipVia |
| ShipPostalCode | nonclustered located on PRIMARY | ShipPostalCode |
Retornemos à pergunta:
“ … Porque não encontramos o processo de BookMark Lookup como parte do plano de execução da query, já que o índice comporta somente uma das colunas presentes no select … “
Para entender porque isso ocorre, teremos que estudar mais a fundo a teoria sobre índices em SQL Server 2000. O corpo de um índice é formado pelas colunas da tabela cujos dados se deseja classificar seguido de uma referência conhecida por “ponteiro”, que serve para localizar a linha na página de dados da tabela. Assim, se o índice não comportar todas as colunas necessárias para resolver a query, a página de dados poderá ser facilmente localizada pela informação do endereço de página obtida no ponteiro do índice.
Existe também um índice especial, conhecido por índice cluster, que não cria uma estrutura à parte da tabela como vimos anteriormente. Um índice cluster irá ordenar as páginas de dados da tabela segundo a estrutura do índice, fazendo com que permaneçam classificadas de acordo com a composição da chave. Pelo fato do índice cluster ordenar a própria página de dados da tabela, podemos criar somente um índice cluster por tabela.
Baseado nessa teoria, sempre que um índice cluster for utilizado na resolução de uma query não existirão processos de BookMark Lookup, pois a linha do índice corresponde à própria linha de dados da própria tabela.
Tudo bem, mas na query anterior, o índice EmployeesOrders não é cluster, e mesmo assim o processo de BookMark Lookup NÃO foi utilizado ....
O que acontece é o seguinte: o ponteiro de um índice não cluster em tabelas que possuam índice cluster será representado pela própria chave do índice cluster e não o RID que identifica a linha na página de dados (id filegroup+id página+id linha).
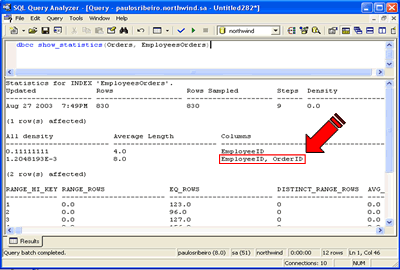
Portanto, o ponteiro do índice EmployeesOrders será representado pela coluna OrderId, que é o índice cluster da tabela Orders. A coluna OrderId, portanto, foi “anexada” à estrutura do índice na forma de um ponteiro. Podemos comprovar esse fato através do comando DBCC Show_Statistics, utilizado para verificar a densidade do índice:
Um pouco de história ...
A troca do RID pelo ponteiro do índice cluster foi introduzido na versão 7.0 por questões de otimização: quando um índice cluster sofre um page-split (quebra de uma página que se encontra totalmente preenchida para acomodar uma inserção), metade das linhas da tabela são alocadas numa nova página. Até a versão 6.5 todos os índices não cluster das linhas movimentadas tinham que ser atualizados, porque mudo-se o RID de dessas linhas. À partir da versão 7.0, com a implementação da chave do índice cluster como ponteiro, nenhum índice sofre atualização: mudam-se as páginas, mas a chave do índice cluster permanece inalterada.
Por hoje é só,
Um forte abraço a todos!
Paulo Ribeiro
 |
Paulo Ribeiro (psribeiro@hotmail.com) é Microsoft MCDBA e membro da equipe editorial da SQL Magazine. Atua como DBA sênior em SQL Server na Livraria e Papelaria Saraiva S/A. |
Todos
os direitos reservados: DevMedia Group
SQL Magazine
- 2004